29 Jan 2024
What the hell is an enshrined bridge?
I’ve been doing a mini self-led rollup bootcamp this week to finally learn about how rollups work. The promises of “high scalability” and “privacy” are all groundbreaking claims that I’ve been wanting to dive deeper on for a while, but also, as a developer I’m always naturally skeptical when I meet something that with lofty claims.
I wanted to synthesize my learnings in the past week by writing about them, both to solidify my knowledge and in the hopes that someone will read this and correct any wrong ideas I still have about rollups in accordance to Cunnhingham’s law.
Mainly, I’ve been trying to make sense of this blog post by Jon Charbonneau. The post summarizes a lot of misconceptions about rollups. I always love diving into thought experiments that result in deriving some new conclusions about systems, so I was thrilled to read this post. But also I found some of the examples and conclusions a bit hard to follow, probably because I don’t have a ton of examples for my mind to grasp on to when trying to reason about things. So I’ll try to give a concrete example here, in an attempt to both give myself an example, and perhaps help someone else who might also find it useful.
I’ll avoid summarizing the post itself, and instead try to independently arrive at some of the same conclusions that Jon arrived at through considering this singular concrete example.
Let’s say we are sick of paying L1 gas fees, want to implement a rollup solution, similar to Optimisim or Arbitrum. We’d want to be able to basically use all of the features of the EVM but somehow make them cheaper through batching up transactions and compressing them. But we want this rollup to be as secure as possible (ideally as secure as the L1 chain). How would such a system look like? The EVM is ultimately just a state machine - so if we can find ways to:
then we have our rollup!
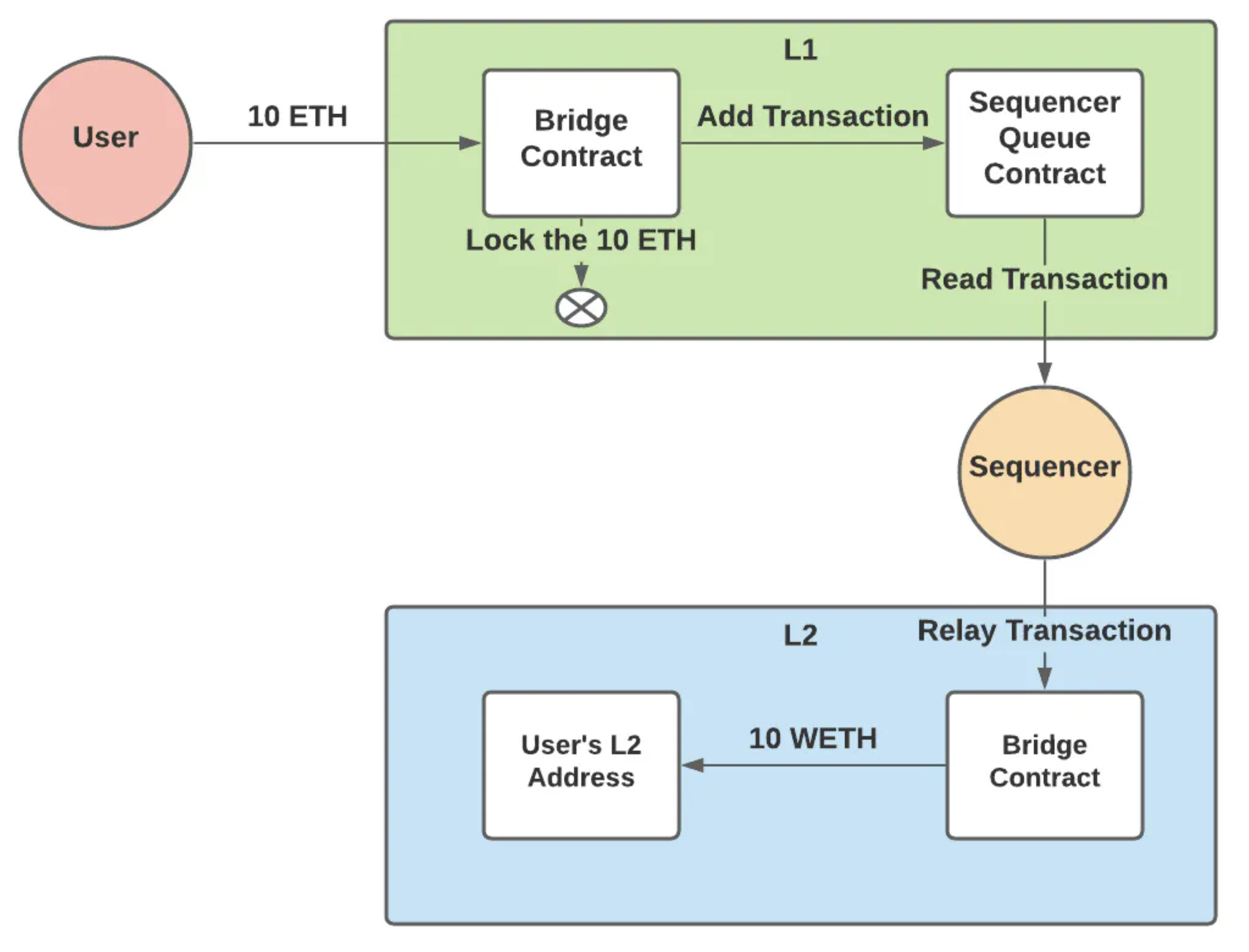
We can use the L1 network itself for storing the state. Transactions can be routed through a smart contract that acts as a queue and once a transaction is routed, it will be immortalized in the historical ethereum state transition set. A sequencer can use this queue to post new blocks to the L2 chain.
To save me on some diagram drawing, I’ll use this diagram I shamelessly got from this Alchemy explanation on how rollups work to illustrate our rollup:
What data will the sequencer contract actually store and how will it look like?
Since we want this rollup primarily to save on gas, we can’t just store all the transactions data on-chain in the queue contract’s storage. That would require similar costs as just operating solely on the L1 chain, and would not save us anything!
But we also want as much security as possible, so we need some way of persisting the the transactions that “get rolled up”. Otherwise, if we didn’t persist them, you’d kind of be at the whims of the sequencer to store all of them. You’d also be screwed if something happened to the sequencer or if it suddenly decided that this bear market has been going on for too long and wants to instead spend it’s time learning Rust. In general, censorship resistance is a widely-touted property of some blockchains, and Ethereum has that, so it would be cool if our rollup did as well. This persistence of data needs to happen on what’s called a Data Availability (DA) layer.
To strike a good balance between cost and data persistence, storing raw rolled-up transaction state is often done through submitting it in calldata. That way, while it’s not available directly on-chain inside contracts in the Ethereum L1, it is immutable and readily available to anyone in the network, since it is part of an L1 transaction, thus forcing it to be persisted for anyone who wishes maintain the full state of the L1. The benefit of using calldata is that it is much much cheaper than storing it in a smart contract directly. What is stored in the contract storage, however, is the merkle tree root of all of the state in our rollup chain. The reason for this will become clearer later in this post! A big part of our overall security hinges on the security of the data availability layer. Since we’re using Ethereum L1 as our DA layer, we can inherit some of the security properties of the L1 chain.
More concretely, the on-chain (on the Ethereum chain, that is) implementation contract would look something like this:
contract OurRollupQueue{
rootMerkleHash: bytes32; // Stores the hash of the merkle root
// This function can be called by the sequencer to submit new blocks
function newBlock(bytes[] calldata transactions, bytes calldata rootmerkleHash ) onlySequencer {
rootMerkleHash = newMerkleHash; // Only the new merkle hash of the state is stored on-chain;
// we don't actually store the transactions on here!
}
}
Ok, so we have a way of storing raw transactions in this rollup, and a way of sending new ones and transitioning between states. Cool. But what do does this have to do with ZK/validity proofs?
We haven’t really said anything about what proving mechanism we’re using to ensure that the state transitions that the sequencer posts are all valid yet, since we’re still designing the rollup itself. I’ll address that shortly, since right now the serializer can post any transaction data and that’s a huge gaping hole in security. But I did want to pause here to note that concrete example shows that the actual design of the rollup isn’t just the proving mechanism. How you batch transactions, how you persist data, how you manage the transitions are all important considerations. The ZK proofs or verification proof stuff is only aimed at ensuring state transitions are valid. They can be swapped out depending on the useability/complexity tradeoff you want to make. You use ZK proofs or Optimistic rollups , but at the end of the day these are just tools for state validation rather than anything that is central to our rollup design.
What is a state transition anyway, and why do we care if they’re valid or not? Since transactions can do anything from sending ether or calling and deploying smart contracts with arbitrary data, transactions can be thought of as state transitions (because they lead to changes either in smart contract state or between ETH balances on addresses).
When a sender posts a transaction to the network, the transactions need to be cryptographically signed by the sender’s private key. Requiring transactions (err, state transitions) to be signed prevents people from spending money that isn’t there. This is already implemented on the L1 - if I were to send an unsigned transaction saying “send 5 ETH from Vitalik’s address to my address thanks bb”, I would get my transaction rejected to whatever full or light node you sent it to in a heartbeat. Since this is how transactions are validated, this is also a big part of defining what a valid state transition is - if a transaction is not signed, it for sure isn’t a valid state transition. There are also other requirements for defining what valid state transitions are (e.g. you can’t send more ether that you have, can’t send a transaction if you don’t have gas money, etc). If you didn’t have state transition validation, then you’d have a very insecure rollup - anyone could send transactions from anyone’s address.
Though we have this for L1 already, we don’t yet have a way to validate transactions for our rollup. That’s where the Zero knowledge/ verification proofs come in - they are used to verify that all transactions that the sequencer sends are correct as per our valid state transition definition. This helps to minimize trust assumptions of operating within our rollup. But again note, this is separate from the actual rollup design we had.
Also note - in this design, while we can verify that all transactions that are posted are valid using the ZK/fraud proofs, we don’t necessarily know that the serializer has omitted any transactions that it should have included. This can be solved through implementing some slashing mechanism for the sequencer - the details of which are out of scope for this post for now.
I also won’t go into the details of how ZK/fraud proofs work, but in general you can assume there will be some way of rolling back or not accepting or not accepting new L2 states that don’t have valid state transition. This will in turn prevent things like people submitting transactions from addresses they don’t own, etc. and also minimize trust in the sequencer.
Even though our rollup might have it’s own native token (which is minted/burned/consumed as gas based on the rules we setup on our own rollup), it is also beneficial to be able to move L1 tokens onto our rollup. That way, we can directly use L1 tokens on our chain, instead of having to mint and manage those on our chain separately.
Typically, the best way to do this is through a bridge contract:
Most bridges require some intermediary that has sole minting/burning rights for both bridge contracts in the L1 and rollup chains. This can be a central source of failure (e.g. if it gets hacked, all tokens that are either escrowed in the bridge from step 1, or minted in the rollup bridge contract from step 2 are at risk of either being stolen or have massive supply inflation). This can occur when you’re bridging across chains, which can sometimes require a trusted set of validators who have minting/burning rights.
To mitigate this, we can have what has been referred to known as an enshrined bridge, where the L1 bridge contract has a direct connection to our rollup bridge contract. Remember the merkle root of all of our rollup state that we’re storing in our contract? That comes in handy here - the merkle root allows us to minimize trust on the bridge by doing things like directly modifying the rollup smart contract state to include wrapped tokens in the state transitions, or also directly use merkle proofs to verify that you have the tokens you’re burning and so that you can directly withdraw them from the L1 bridge (see here).
The bridge contract deployed on Ethereum L1 might look something like this:
contract RollupBridge{ // This contract will be deployed on L1 and is where users deposit their tokens they want bridged
// Deposit an L1 token to back the corresponding token on the rollup chain, probably requires user to pre-approve this token to spend here
function deposit(address token, uint256 tokenAmount) {
token.transferFrom(tokenAmount, msg.sender, address(this) );
// After the token is transferred and held, more tokens can be minted on the L2 chain.
}
// Withdraw L1 by submitting a merkle proof that you have at least x amount of tokens in your account on the rollup chain
function withdraw(address token, uint256 withdrawAmount, bytes[] calldata withdrawProof){
bytes hash = keccak256(abi.encodePacked(token, withdrawAmount, msg.sender)); // The state transition that you are actually proving
for (uint i = 0; i < withdrawProof.length; i++) {
hash = keccak256(abi.encodePacked(hash, withdrawProof[i]));
}
// If the state you're claiming to have is valid, it will be part of a tree which has merkle root
require (hash == rollupContract.getRootMerkleHash(), "Invalid merkle proof");
token.transfer(withdrawAmount, msg.sender);
}
}
The bridging is where a lot of the rollup complexity kicks in, and a lot of nuance in the security of the bridge.
Note that in this implementation, the bridge contract was completely separate from the rollup contract. You might give the bridge contract special access control to, let’s say, post state transitions to the rollup contract to reflect users bridging tokens. But the bridge contract is still largely limited in the impact it can have on the rollup contract and the rollup client. Just like how ERC20 tokens on Ethereum don’t impact the security of the Ethereum network itself, the bridge only impacts the security of bridged token. A bridge hack might make it so that the entire supply of some token on the rollup chain is unbacked or inflated, but that still doesn’t mess with any security of other smart contracts deployed on the rollup (assuming they don’t use the hacked token), or the rollup state consensus or the data persistance.
bridge != rollup
To pwn a rollup, you’d need to specifically find some vulnerability in the rollup smart contract, or somehow deny/delay all sequencer who have access rights to post new rollup blocks from doing so, or to find a bug in the rollup client.
Each chain is it’s own L1, but when bridged, it is it’s own L2
When you bridge L1 ethereum across our smart contract bridge, it will be a second-class token on our rollup network. Our bridge contract certainly does not have rights to mint native ETH - that can only be done through the rules of how ETH minting is implemented on the client. So when we bridge ETH, we have to wrap a token that is backed by the ETH (or whatever currency we bridge) we deposit to our bridge. Our bridge will have minting rights to the wrapped token only.
That was like the first half of Jon’s post - I’ll leave trying to extend this example to reason about the second half for another time!